

The corpora in ICE are being
annotated at various levels to enhance their value in linguistic research.
These levels are
- Textual Markup
- Wordclass Tagging
- Syntactic Parsing
Textual Markup
In written texts, features
of the original layout are marked, including sentence and paragraph boundaries,
headings, deletions, and typographic features.
Spoken texts are transcribed orthographically, and are marked for pauses, overlapping strings, discourse phenomena such as false starts and hesitations, and speaker turns.
The markup manual is available here.
Wordclass Tagging
ICE texts are automatically
tagged for wordclass by the ICE Tagger, developed by Sean Wallis at the Survey of English Usage, University College London. This assigns wordclass
tags to each lexical item in the corpus. The tagset has been developed
especially for ICE, and is largely based on Quirk et al (1985) A Comprehensive
Grammar of the English Language. An example of a grammatically tagged
sentence is shown below:
| Each | PRON(univ,sing) |
| of | PREP(ge) |
| these | PRON(dem,plu) |
| is | V(cop,pres) |
| the | ART(def) |
| responsibility | N(com,sing) |
| of | PREP(ge) |
| one | NUM(card,sing) |
| person | N(com,sing) |
The tagging manual is available here
Syntactic Parsing
Every
sentence in the corpus is analysed at phrase, clause, and sentence level,
and the analysis is shown in the form of a parse tree:
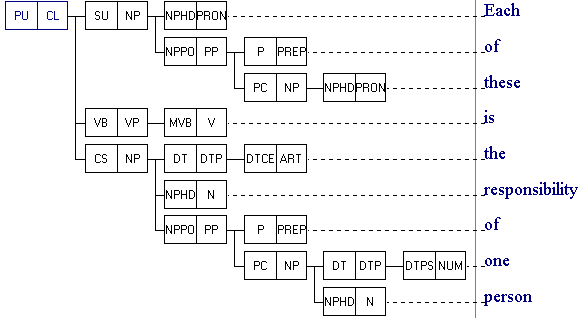
For more details about the
grammatical annotation, see the Quick
Guide to the ICE-GB Grammar (on the UCL server).
The parse trees are edited and corrected, if necessary, using a version of ICECUP, a dedicated syntactic tree editor and retrieval system which has been developed specifically for ICE.
In addition to the annotation levels
above, some ICE teams will digitize their sound recordings, aligning them
with the orthographic transcriptions. The British team has completed the digitization and alignment stage. The American team is adding detailed prosodic annotations
to their transcriptions of spoken texts.
The ICE-Ireland team have produced a version of their corpus with pragmatic annotation.
© 2009 The ICE Project